
Inhoudsopgave
- Wat is een zoekmachine?
- Wat gebeurt er als je iets googelt?
- Hoe de zoekmachine aan die enorme database aan websites komt
- Hoe de zoekmachine beslist welke websites getoond worden
- In het kort

Deel dit artikel
Deze pagina direct samenvatten
Ontdek de wereld van zoekmachines! Leer over complexe algoritmes die zoekresultaten vormgeven. Leer alles over het algoritme en ontrafel de geheimen achter jouw zoekopdrachten.
Zoekmachines zijn enorm vernuftige, slimme programma’s die jou helpen alles op het wereldwijde web te vinden. Hun ‘spiders’ of ‘crawlers’ bezoeken elke pagina die ze maar kunnen vinden, de zoekmachine slaat die op in de index en met behulp van een algoritme geeft Google of Bing jou vervolgens de meest relevante resultaten voor de zoekopdracht die jij zojuist hebt ingetypt. Ging dat wat te snel? Geen probleem, we leggen het hieronder nog wat uitgebreider uit.
Na het lezen van dit artikel weet je:
- Wat een zoekmachine is;
- Wat er aan de voorkant gebeurt als je iets googelt;
- Wat er aan de achterkant gebeurt in de zoekmachine.
Wat is een zoekmachine?
Eerst even back to basics: wat is een zoekmachine? Een zoekmachine is, heel feitelijk, een programma waarmee je informatie kunt zoeken in een bepaalde database. Bij de zoekmachines waar wij het over hebben in dit artikel, zoals Google en Bing, zit bijna het hele wereldwijde web in die database. Op basis van trefwoorden die jij als gebruiker invoert, probeert het algoritme van de zoekmachine precies die webpagina aan je voor te leggen die jij nodig hebt. Net als een bibliothecaris doet als je in de bieb vraagt in welke boeken je bepaalde informatie kunt vinden. Maar dan niet met boeken, maar met miljarden URLs.

Er bestaan meer zoekmachines dan Google
Er zijn een heleboel verschillende zoekmachines. De allergrootste en meest bekende is natuurlijk Google. Met een marktaandeel van meer dan 90 procent in Nederland laat deze Amerikaanse gigant zijn concurrenten vér achter zich. De grootste uitdager van Google is Bing, eigendom van Microsoft. Maar in Nederland pakt Bing slechts rond de 5 procent marktaandeel. Yahoo! en DuckDuckGo ken je misschien ook wel, maar heb je wel eens gehoord van Yandex (de serieuze concurrent voor Google in Rusland), Ecosia (plant bomen voor elke zoekopdracht die gedaan wordt) of Baidu (de Chinese internetreus)? En, misschien nog wel belangrijker: wist je dat Apple ook een zoekmachine aan het ontwikkelen lijkt te zijn?
Omdat Google in ieder geval in Nederland en de rest van Europa de grootste zoekmachine is, richt iedereen die zich hier met SEO bezighoudt zich dan ook op Google en diens algoritme. Marktleider staat in dit geval dus gelijk aan marktbepaler: als Google wil dat je je website op een bepaalde manier inricht, kun je eigenlijk niet anders dan die richtlijnen volgen. Gelukkig werken de meeste zoekmachines in de basis op dezelfde manier en zullen je SEO efforts ook (enig) resultaat boeken in andere zoekmachines dan Google.

Wat gebeurt er als je iets googelt?
Wacht, heb je echt nog helemaal nóóit iets gegoogeld? Dat geloven we niet. Maar oké, we leggen toch nog even snel uit hoe het er aan de voorkant aan toegaat.
Stel, je tikt het zoekwoord [koffie] in in de zoekbalk van Google. Binnen enkele luttele milliseconden verschijnt er een zoekresultatenpagina voor je neus waar allemaal resultaten op staan die jou hopelijk helpen met precies datgene vinden waarnaar je op zoek was. Er staan zo’n 44 miljoen pagina’s klaar om jou te helpen, maar er staan er doorgaans maar negen à tien op de eerste pagina van Google. Voordat je überhaupt naar het pijltje naar de volgende pagina hebt weten te scrollen, ben je al afgeleid door kleurige afbeeldingen, een landkaartje, advertenties, video’s, zoeksuggesties, sterrenbeoordelingen en zelfs de voedingswaarde van koffie. En natuurlijk de normale resultaten! Je kunt wel héél goed tegen verleidingen als je de onderkant van de pagina haalt, laat staan op het pijltje klikt. Ze zeggen niet voor niets dat de tweede pagina van Google de beste plek is om een lijk te verbergen. Wil je weten welke afleidingen op de zoekresultatenpagina er allemaal bestaan? Lees dan ons artikel over SERPs.
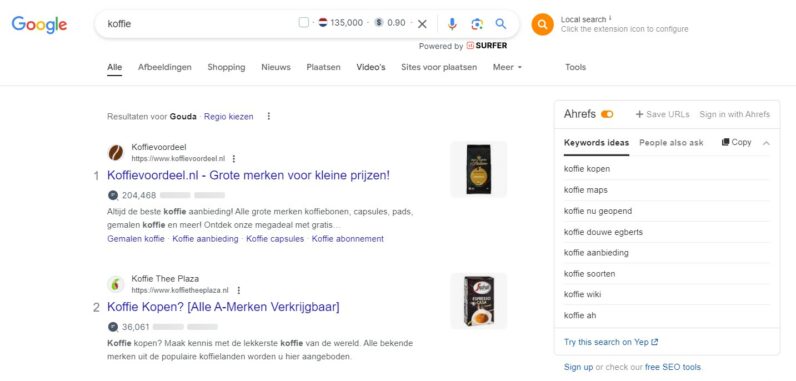
Maar goed, ondertussen heb jij al geklikt op een zoekresultaat waarvan je vermoedt dat die het beste jouw vragen beantwoordt. Misschien wilde je lezen over de geschiedenis van koffie: dan klik je waarschijnlijk op een resultaat van Wikipedia. Wil je ergens op een terrasje een kopje koffie drinken? Dan ben je waarschijnlijk direct het Google Maps-resultaat ingedoken. Zet je liever thuis koffie, maar is je bonenvoorraad bijna op? Dan heb je keuze te over tussen de vele webshops die een plekje hebben weten de bemachtigen op die eerste pagina van Google. En zodoende ben jij op je plek van bestemming terechtgekomen en heeft de zoekmachine zijn taak (hopelijk) succesvol volbracht.
Hoe de zoekmachine aan die enorme database aan websites komt
Het is niet zo dat Google het wereldwijde web pas gaat afstruinen als jij [koffie] hebt ingetikt. Google kijkt in zijn database, de ‘index’, en beslist met zijn algoritme welke pagina’s jij te zien krijgt. Maar hoe bouwt Google die enorme index op? Met crawlers, ook wel spiders genoemd. Dat zijn bots die alle content bezoeken (‘crawlen’) die ze maar tegenkomen en by default elke URL die ze bezoeken opslaan in de index (‘indexeren’). Content ‘tegenkomen’ doen ze op dezelfde manier als jij: via een hyperlink. Elke pagina wordt gescand voor linkjes naar een andere pagina die de bot kan volgen. En zo crawlt de bot 24/7 heel het internet, op zoek naar nieuwe content én controlerend of er iets veranderd is aan de content op al geïndexeerde pagina’s.
Als er geen enkele pagina naar jouw website linkt, zal Googlebot jouw website dus niet kunnen crawlen, laat staan opnemen in de index. En dan zal je website dus ook niet gaan ranken. Een ‘crawl-friendly’ website is dus een belangrijke basis als je aan de slag gaat met SEO.

Hoe de zoekmachine beslist welke websites getoond worden
Nu komen we bij de kern van de zaak: hoe werkt dat ranken? Hoe kiest de zoekmachine uit welke pagina’s hij voor jouw specifieke zoekopdracht laat zien? En hoe komt die volgorde tot stand? Google heeft hier een algoritme voor, dat bij elke zoekopdracht op volle toeren draait om de meest relevante resultaten uit de index te kiezen.
Waar let het algoritme op?
Welke factoren er allemaal precies meespelen bij dat rankingproces is een goed bewaard geheim. En hoe zwaar ze meetellen, is ook nog eens afhankelijk van de aard van de zoekopdracht in kwestie. Hoewel we niet precies kunnen weten hoe het er onder de motorkap aan toegaat, kunnen we door middel van testen en officiële uitingen van Google wel een beeld schetsen.
Je moet je bedenken dat het de missie van Google is om jou, de gebruiker, het best mogelijke antwoord te geven op de vraag die jij hebt. Je hebt niets aan informatie over tijgers of wasmachines als je zoekt op [koffie]. Relevantie is dus een belangrijke factor. De makkelijkste manier om de relevantie van jouw pagina voor [koffie] tentoon te spreiden, is om dat zoekwoord te gebruiken op de website. Maar pas op voor keyword stuffing: Google begrijpt al heel lang dat honderd keer het woord ‘koffie’ achter elkaar niet datgene is waar een gebruiker behoefte aan heeft. Dat brengt ons bij het volgende belangrijke punt: kwaliteit van de content. Welke tekst over de geschiedenis van koffie denk je dat betrouwbaarder is: eentje die geschreven is door een barista, of door je buurman?
In de basis wil Google dus relevante en kwalitatieve resultaten laten zien. Omdat het ondoenlijk is om elke webpagina door een mens te laten lezen en te beoordelen (wist je dat er naar schatting meer dan 4 miljard webpagina’s bestaan?), kent Googles algoritme heel veel ranking factors, op basis waarvan de relevantie en kwaliteit van content worden gemeten. Benieuwd welke factoren er zoal zijn? Lees dan ons artikel over ranking factors.

Google staat nooit stil
Regelmatig wordt het algoritme van Google geüpdatet, aangescherpt en aangevuld. Dan gaat het meestal over kleine updates waar je weinig van zult merken. Maar soms wordt er een grote update doorgevoerd (een ‘core update’) en schudt de SEO-wereld even op zijn grondvesten. Partijen die dachten dat ze veilig op de eerste plek stonden zien hun koninkrijk afbrokkelen, terwijl websites die maar niet op wisten te klimmen opeens een jetpack aan lijken te hebben. Op het moment van schrijven (september 2020) was de meest recente grote update de May 2020 Core Update. Door deze update heeft E-A-T een belangrijkere plaats ingenomen in het algoritme. Lees daar alles over in ons blog over wat E-A-T is en hoe E-A-T jouw business raakt.
In het kort
Let’s recap: wat hebben we allemaal besproken in dit artikel? Behoorlijk veel: je hebt nu een stevig fundament gelegd op het gebied van zoekmachines. Was het ietsje té veel? We vatten het nog even voor je samen:
- Een zoekmachine is een programma waarmee je een database doorzoekt op basis van trefwoorden. Google is de grootste ter wereld en heeft een database met miljarden URLs.
- De bots van een zoekmachine crawlen non-stop webpagina’s en navigeren door het internet via linkjes. Gecrawlde pagina’s worden (in principe) opgenomen in de index.
- Als jij iets googelt, kiest en ordent een algoritme pagina’s uit de index waarvan het denkt dat ze de beste resultaten voor jou zijn op basis van je zoektermen die je gebruikt.
- Hoe het algoritme die pagina’s uitkiest en in een bepaalde volgorde zet, is niet openbaar bekend. Maar we weten wel dat Google waarde hecht aan relevantie en kwaliteit.
Meer weten over SEO? We hebben een hele SEO kennisbank voor je. Allemaal handige artikelen met bruikbare informatie die onze specialisten met alle liefde delen met de wereld!

